|
Hi, I am a final-year CS Ph.D. Student at the Computer Science Department of Yale University, working on large language models, natural language processing and machine learning. I am fortunate to be advised by Professor Rex Ying, Professor Kathleen McKeown (from Columbia University), and Professor Dragomir Radev. My main research directions are in large language models, LLM-powered reinforcement learning, knowledge and logical reasoning, neuro-symbolic reasoning and multimodal language grounding. I am also very interested in the application of large language models and deep learning in quantitative finance. Before coming to Yale, I obtained my Master of Science degree in Computer Science from Stanford University, where I conducted research in machine learning, computer vision and robotics at the Stanford Artificial Intelligence Laboratory. Prior to that, I spent four wonderful undergraduate years at Harvard University and received my Bachelor of Arts degree in Computer Science with a secondary field in Economics from Harvard. I have also worked in the Machine Learning Department of Carnegie Mellon University for one year conducting research on machine learning theories. At CMU I work with Professor Geoff Gordon to design and study new learning algorithms for general latent-variable graphical models. Email / Google Scholar / LinkedIn [On the Job Market] I am currently on the job market for 2025/2026. Please feel free to reach out to me if you have open positions that you think I might be a good fit for. Thank you! |

|
|
|
|
|
Borui Wang, Kathleen McKeown, Rex Ying Preprint Reinforcement learning from expert demonstrations has long remained a challenging research problem, and existing state-of-the-art methods using behavioral cloning plus further RL training often suffer from poor generalization, low sample efficiency, and poor model interpretability. Inspired by the strong reasoning abilities of large language models (LLMs), we propose a novel strategy-based reinforcement learning framework integrated with LLMs called DYnamic STrategy Induction with Llms for reinforcement learning (DYSTIL) to overcome these limitations. DYSTIL dynamically queries a strategy-generating LLM to induce textual strategies based on advantage estimations and expert demonstrations, and gradually internalizes induced strategies into the RL agent through policy optimization to improve its performance through boosting policy generalization and enhancing sample efficiency. It also provides a direct textual channel to observe and interpret the evolution of the policy's underlying strategies during training. We test DYSTIL over challenging RL environments from Minigrid and BabyAI, and empirically demonstrate that DYSTIL significantly outperforms state-of-the-art baseline methods by 17.75% in average success rate while also enjoying higher sample efficiency during the learning process. |
|
|
Borui Wang, Qiuyuan Huang, Budhaditya Deb, Aaron Halfaker, Liqun Shao, Daniel McDuff, Ahmed Hassan Awadallah, Dragomir Radev, Jianfeng Gao In Findings of the Association for Computational Linguistics: ACL 2023. ACL 2023 Findings [arXiv] Natural language contains rich logical structures and logical information, and correctly detecting and accurately understanding these logical structures and information underlying natural language texts is very crucial for NLP models' performance on many important NLU and NLG tasks. Existing pre-trained language models based on the transformer architecture mostly adopt a classical design for constructing their input embeddings that ignores the logical structures underlying natural language texts, thus limiting their ability to better capture and encode key logical information in the input sequences. To overcome such limitations, in this paper we first propose a novel approach to construct logic-aware input embeddings for transformer language models through a combination of logic detection, logic mapping and hierarchical logical projections, and then develop a corresponding new modeling paradigm that can upgrade existing transformer language models into logical transformers to boost their performance on different NLU and NLG tasks. Our empirical experiments on four important and challenging NLU and NLG tasks demonstrate that our proposed logical transformer language models can achieve superior performance over their baseline transformer models through a deeper understanding of the logical structures of texts. |
|
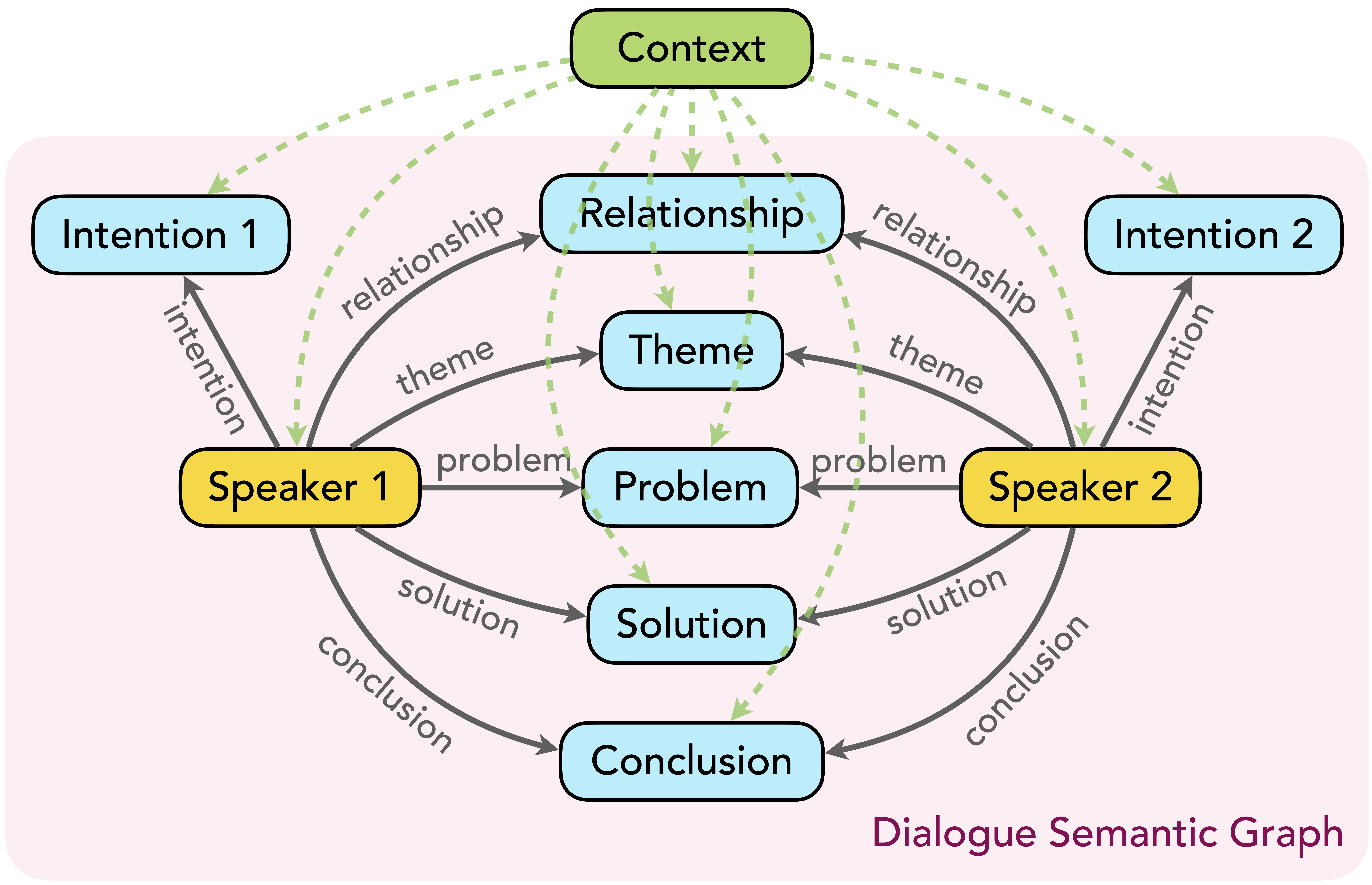
Borui Wang, Chengcheng Feng, Arjun Nair, Madelyn Mao, Jai Desai, Asli Celikyilmaz, Haoran Li, Yashar Mehdad and Dragomir Radev In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP). EMNLP 2022 [arXiv] In this paper, we propose a novel type of dialogue summarization task - STRUctured DiaLoguE Summarization (STRUDEL) - that can help pre-trained language models to better understand dialogues and improve their performance on important dialogue comprehension tasks. We further collect human annotations of STRUDEL summaries over 400 dialogues and introduce a new STRUDEL dialogue comprehension modeling framework that integrates STRUDEL into a graph-neural-network-based dialogue reasoning module over transformer encoder language models to improve their dialogue comprehension abilities. In our empirical experiments on two important downstream dialogue comprehension tasks - dialogue question answering and dialogue response prediction - we show that our STRUDEL dialogue comprehension model can significantly improve the dialogue comprehension performance of transformer encoder language models. |
|
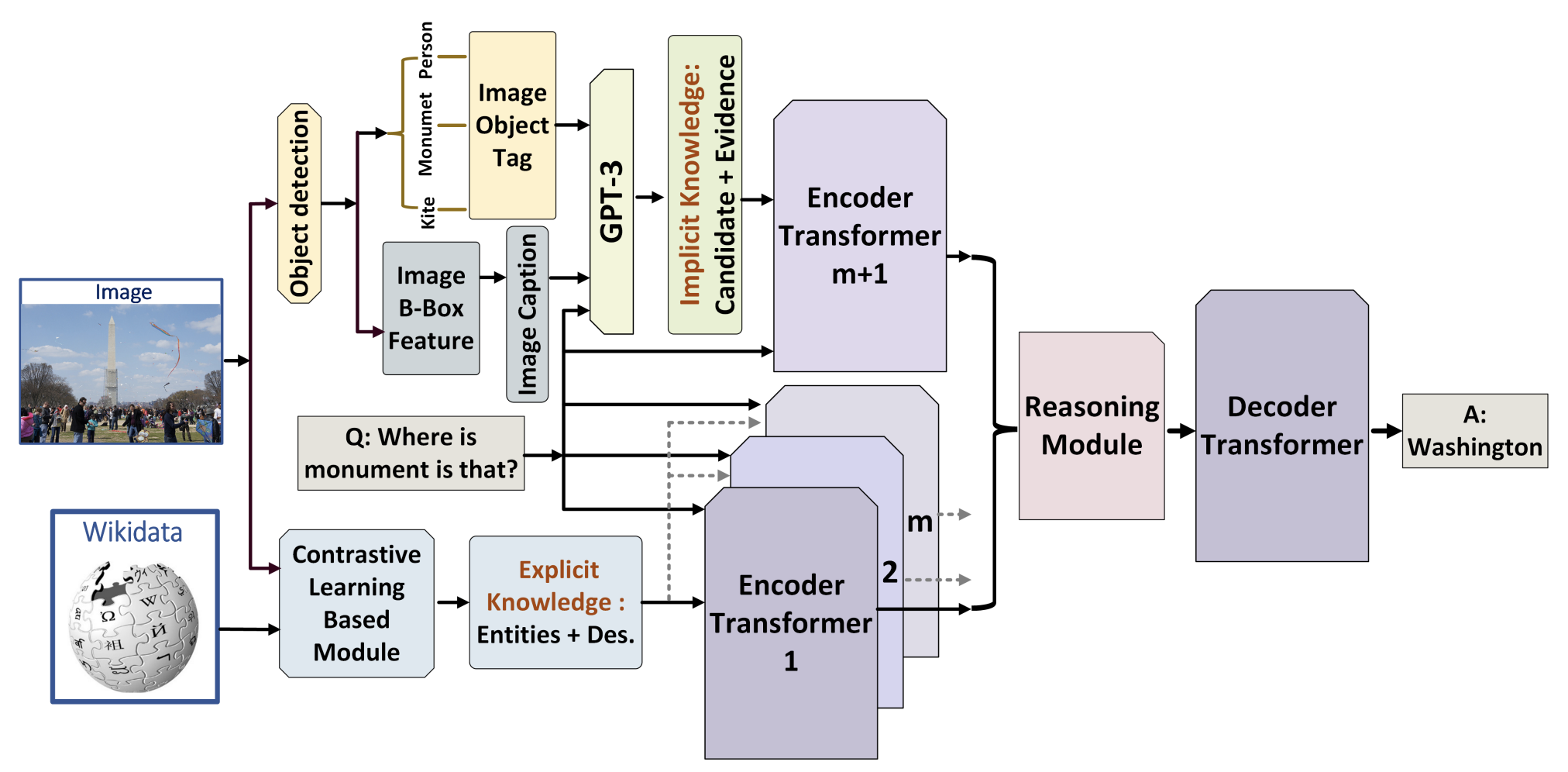
Liangke Gui, Borui Wang, Qiuyuan Huang, Alex Hauptmann, Yonatan Bisk, Jianfeng Gao In Proceedings of the 2022 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL). NAACL 2022 [arXiv] The primary focus of recent work with largescale transformers has been on optimizing the amount of information packed into the model's parameters. In this work, we ask a different question: Can multimodal transformers leverage explicit knowledge in their reasoning? Existing, primarily unimodal, methods have explored approaches under the paradigm of knowledge retrieval followed by answer prediction, but leave open questions about the quality and relevance of the retrieved knowledge used, and how the reasoning processes over implicit and explicit knowledge should be integrated. To address these challenges, we propose a novel model - Knowledge Augmented Transformer (KAT) - which achieves a strong state-of-the-art result (+6 points absolute) on the open-domain multimodal task of OK-VQA. Our approach integrates implicit and explicit knowledge in an end to end encoder-decoder architecture, while still jointly reasoning over both knowledge sources during answer generation. An additional benefit of explicit knowledge integration is seen in improved interpretability of model predictions in our analysis. |
|
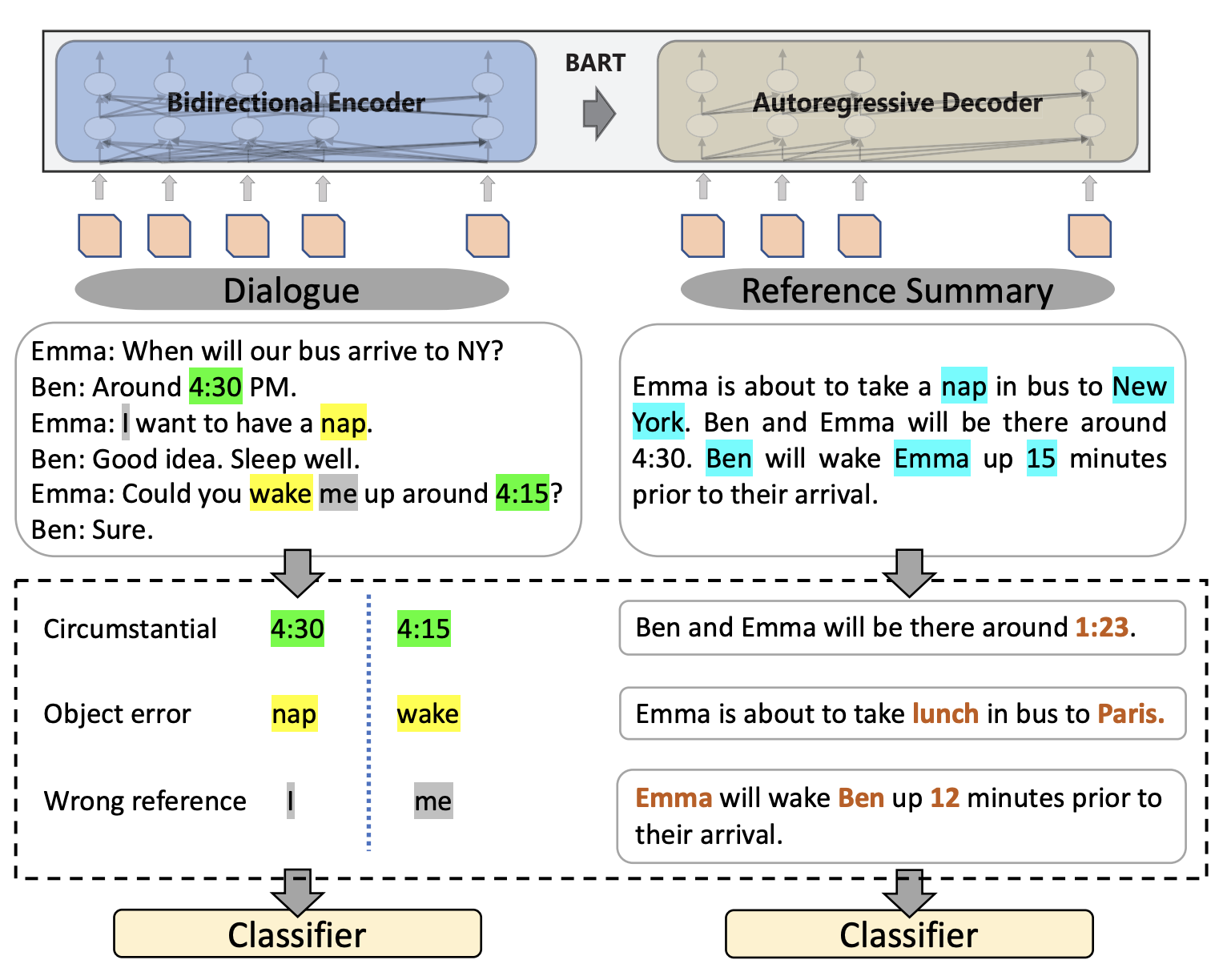
Xiangru Tang, Arjun Nair, Borui Wang, Bingyao Wang, Jai Desai, Aaron Wade, Haoran Li, Asli Celikyilmaz, Yashar Mehdad, Dragomir Radev In Proceedings of the 2022 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL). NAACL 2022 [arXiv] Factual inconsistencies in generated summaries severely limit the practical applications of abstractive dialogue summarization. Although significant progress has been achieved by using pre-trained models, substantial amounts of hallucinated content are found during the human evaluation. Pre-trained models are most commonly fine-tuned with cross-entropy loss for text summarization, which may not be an optimal strategy. In this work, we provide a typology of factual errors with annotation data to highlight the types of errors and move away from a binary understanding of factuality. We further propose a training strategy that improves the factual consistency and overall quality of summaries via a novel contrastive fine-tuning, called ConFiT. Based on our linguistically-informed typology of errors, we design different modular objectives that each target a specific type. Specifically, we utilize hard negative samples with errors to reduce the generation of factual inconsistency. In order to capture the key information between speakers, we also design a dialogue-specific loss. Using human evaluation and automatic faithfulness metrics, we show that our model significantly reduces all kinds of factual errors on the dialogue summarization, SAMSum corpus. Moreover, our model could be generalized to the meeting summarization, AMI corpus, and it produces significantly higher scores than most of the baselines on both datasets regarding word-overlap metrics. |
|
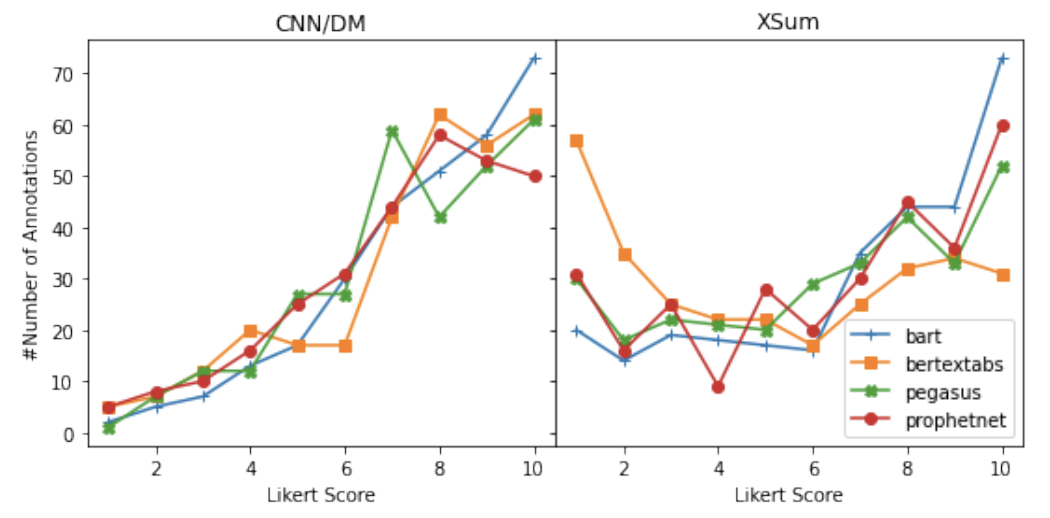
Xiangru Tang, Alexander R. Fabbri, Ziming Mao, Griffin Adams, Borui Wang, Haoran Li, Yashar Mehdad, Dragomir Radev In Proceedings of the 2022 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL). NAACL 2022 [arXiv] Current pre-trained models applied to summarization are prone to factual inconsistencies which either misrepresent the source text or introduce extraneous information. Thus, comparing the factual consistency of summaries is necessary as we develop improved models. However, the optimal human evaluation setup for factual consistency has not been standardized. To address this issue, we crowdsourced evaluations for factual consistency using the rating-based Likert scale and ranking-based Best-Worst Scaling protocols, on 100 articles from each of the CNN-Daily Mail and XSum datasets over four state-of-the-art models, to determine the most reliable evaluation framework. We find that ranking-based protocols offer a more reliable measure of summary quality across datasets, while the reliability of Likert ratings depends on the target dataset and the evaluation design. Our crowdsourcing templates and summary evaluations will be publicly available to facilitate future research on factual consistency in summarization. |
|
Alexander R. Fabbri, Faiaz Rahman, Imad Rizvi, Borui Wang, Haoran Li, Yashar Mehdad, Dragomir Radev In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL), 2021. ACL 2021 [arXiv] Factual inconsistencies in generated summaries severely limit the practical applications of abstractive dialogue summarization. Although significant progress has been achieved by using pre-trained models, substantial amounts of hallucinated content are found during the human evaluation. Pre-trained models are most commonly fine-tuned with cross-entropy loss for text summarization, which may not be an optimal strategy. In this work, we provide a typology of factual errors with annotation data to highlight the types of errors and move away from a binary understanding of factuality. We further propose a training strategy that improves the factual consistency and overall quality of summaries via a novel contrastive fine-tuning, called ConFiT. Based on our linguistically-informed typology of errors, we design different modular objectives that each target a specific type. Specifically, we utilize hard negative samples with errors to reduce the generation of factual inconsistency. In order to capture the key information between speakers, we also design a dialogue-specific loss. Using human evaluation and automatic faithfulness metrics, we show that our model significantly reduces all kinds of factual errors on the dialogue summarization, SAMSum corpus. Moreover, our model could be generalized to the meeting summarization, AMI corpus, and it produces significantly higher scores than most of the baselines on both datasets regarding word-overlap metrics. |
|
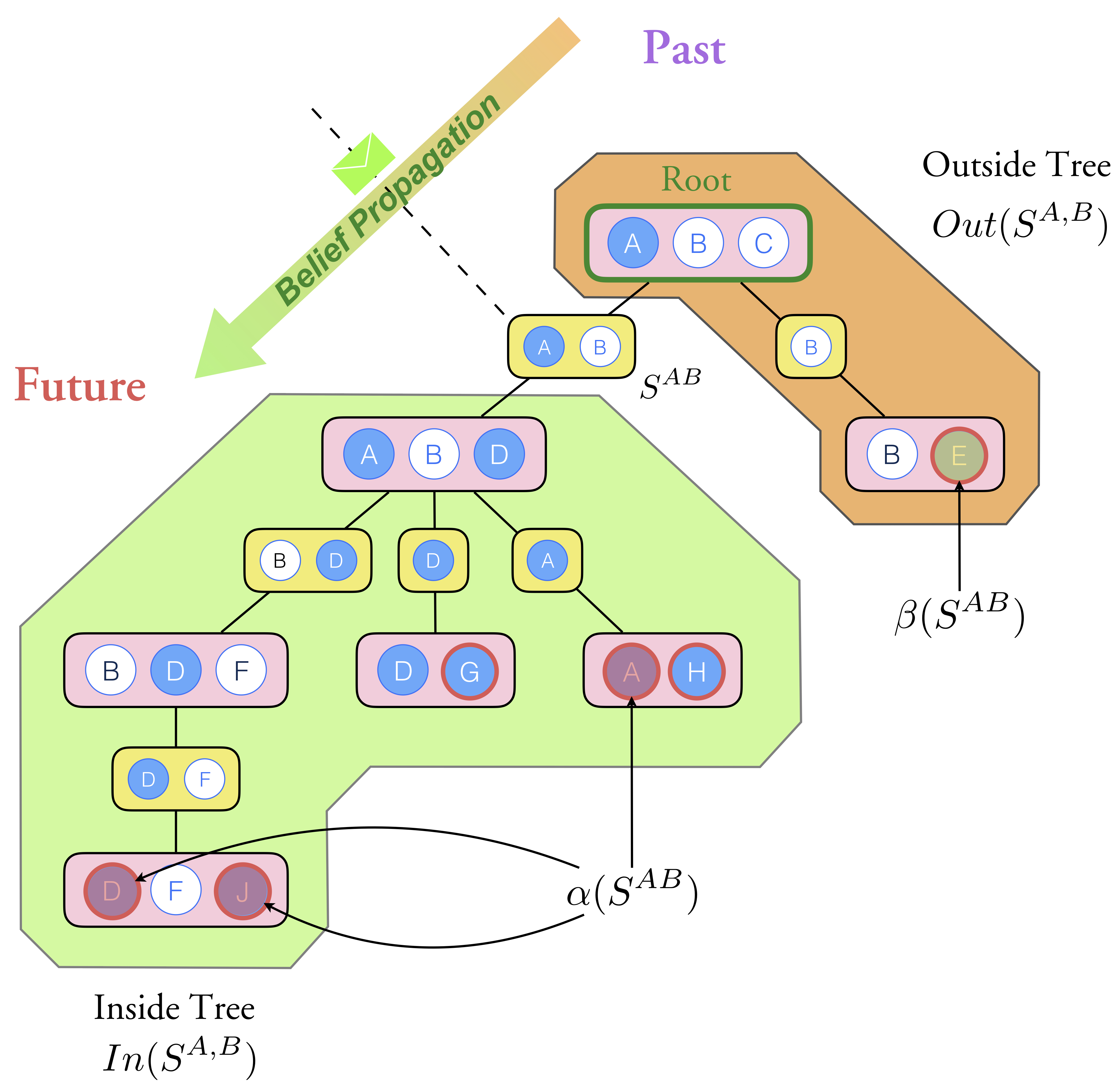
Borui Wang, Geoffrey Gordon In Proceedings of the 34th AAAI Conference on Artificial Intelligence (AAAI), 2020. AAAI 2020 [arXiv] We introduce a novel formulation of message-passing inference over junction trees named predictive belief propagation, and propose a new learning and inference algorithm for general latent-variable graphical models based on this formulation. Our proposed algorithm reduces the hard parameter learning problem into a sequence of supervised learning problems, and unifies the learning of different kinds of latent graphical models into a single learning framework that is local-optima-free and statistically consistent. |
|
Borui Wang, Ehsan Adeli, Hsu-kuang Chiu, De-An Huang, Juan Carlos Niebles In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019. ICCV 2019 [arXiv] / [CVF Open Access] We propose a new reinforcement learning formulation for the problem of human pose prediction in videos, and develop an imitation learning algorithm for predicting future poses under this formulation through a combination of behavioral cloning and generative adversarial imitation learning. |
|
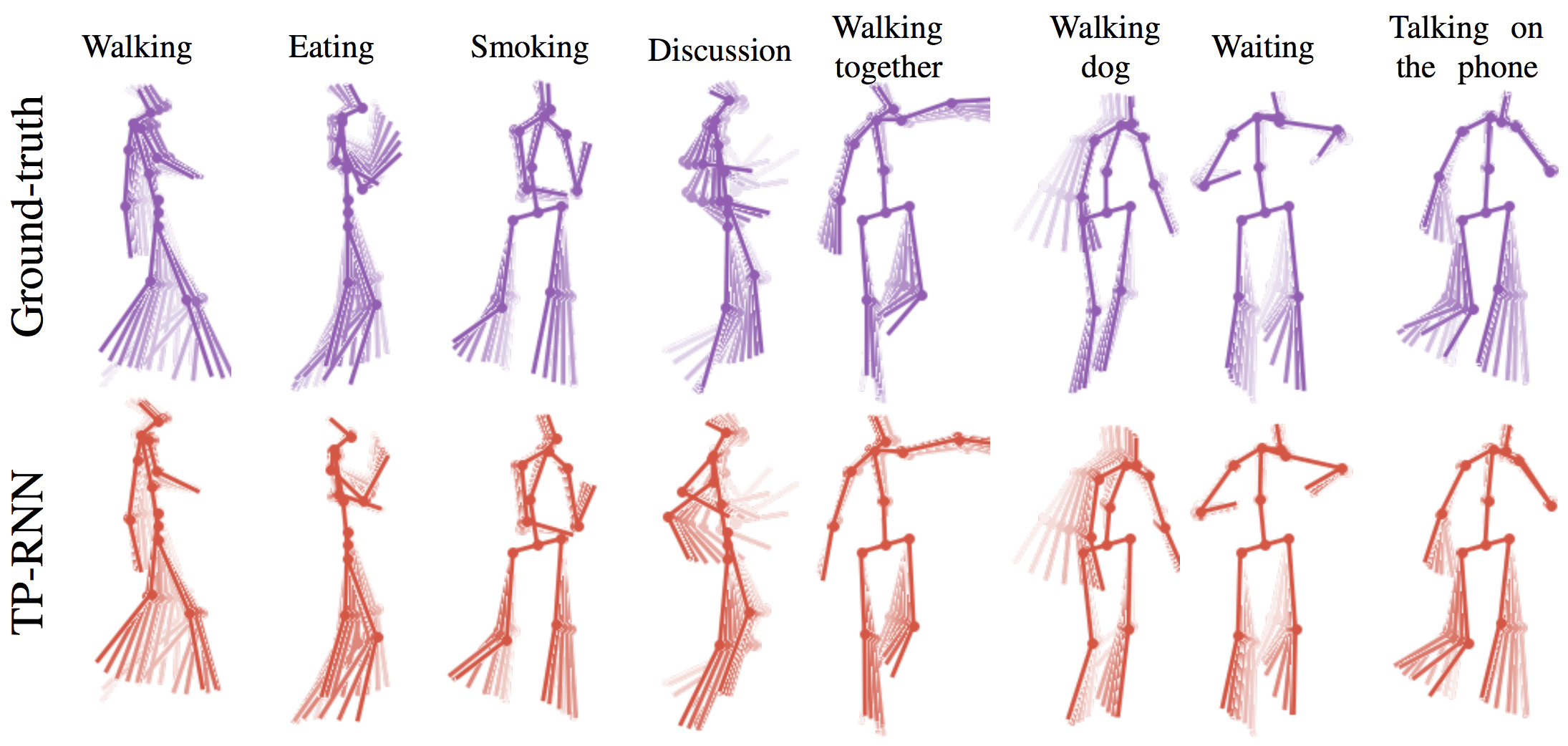
Hsu-kuang Chiu, Ehsan Adeli, Borui Wang, De-An Huang, Juan Carlos Niebles In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), 2019 WACV 2019 [arXiv] We propose a new action-agnostic method for both short-term and long-term human pose forecasting. To this end, we propose a new recurrent neural network for modeling the hierarchical and multi-scale characteristics of the human motion dynamics, denoted by triangular-prism RNN (TP-RNN). Our model captures the latent hierarchical structure embedded in temporal human pose sequences by encoding the temporal dependencies with different time-scales. |
|
|